


Meta推出首个支持语音文字同时输入的AI音频生成模型“Audiobox”
近日,Meta发布了最新的AI音频生成模型“Audiobox”。该模型以Meta 6月发布的Voicebox框架为基础开发,能生成各种环境及风格的语音、音效,同时整合了生成、编辑能力,以及多种输入机制,增强了对不同应用场景的声音控制能力。
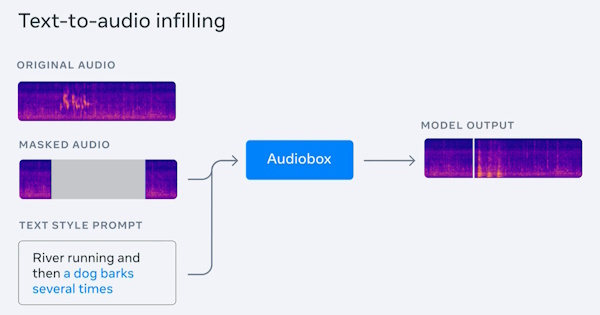
在Meta看来,Audiobox是第一个可接受语音及文字描述来改造声音的模型。通过Audiobox,用户可以运用自然语言文字提示描述想要的声音或语音类型,例如可输入“流水环境中的鸟叫声”等文字信息生成场景音效,或是输入“高声调、快节奏讲话的年轻女性”生成人声。 此外,用户还可以输入人声及文字信息,合成在指定环境下带有情绪起伏的一段对话。
Audiobox目前已经开放向特定研究人员及学术界试用,以测试模型质量及安全伦理性,未来几周后还将通过网页开放试用申请。
上一篇:《Braid》的创作者Jonathan Blow正在组建团队开发首款VR游戏[ 12-07 ]
下一篇:没有了!

