


带你了解世界最先进的手势识别技术 -- 微软,凌感,Leap...

雷锋网编者按:本文作者是王元、高羽,uSens凌感科技的员工。不知道大家还记不记得02年的好莱坞电影《少数派报告》?小编当时疯狂痴迷汤姆克鲁斯饰演的精英探员,不仅仅是因为汤姆克鲁斯本身的魅力,还因为电影里展示的酷炫的手势操作界面。有人说,电影在一定程度上是人类技术的先知,这个论调虽然不能说完全正确,但是在手势控制的人机交互这方面,我们从来没有像现在一样接近未来。今天就让小编为大家解释一下现有的几种主要的手势识别技术,为你揭开手势识别技术的神秘面纱。
概述
谈起手势识别技术,由简单粗略的到复杂精细的,大致可以分为三个等级:二维手型识别、二维手势识别、三维手势识别。
在具体讨论手势识别之前,我们有必要先知道二维和三维的差别。二维只是一个平面空间,我们可以用(X坐标,Y坐标)组成的坐标信息来表示一个物体在二维空间中的坐标位置,就像是一幅画出现在一面墙上的位置。三维则在此基础上增加了“深度”(Z坐标)的信息,这是二维所不包含的。这里的“深度”并不是咱们现实生活中所说的那个深度,这个“深度”表达的是“纵深”,理解为相对于眼睛的“远度”也许更加贴切。就像是鱼缸中的金鱼,它可以在你面前上下左右的游动,也可能离你更远或者更近。
前两种手势识别技术,完全是基于二维层面的,它们只需要不含深度信息的二维信息作为输入即可。就像平时拍照所得的相片就包含了二维信息一样,我们只需要使用单个摄像头捕捉到的二维图像作为输入,然后通过计算机视觉技术对输入的二维图像进行分析,获取信息,从而实现手势识别。
而第三种手势识别技术,是基于三维层面的。三维手势识别与二维手势识别的最根本区别就在于,三维手势识别需要的输入是包含有深度的信息,这就使得三维手势识别在硬件和软件两方面都比二维手势识别要复杂得多。对于一般的简单操作,比如只是想在播放视频的时候暂停或者继续放映,二维手势也就足够了。但是对于一些复杂的人机交互,比如玩游戏或者应用在VR(虚拟现实)上,三维手势实在是居家旅行必备、舍我其谁的不二之选。
手势识别分类
二维手型识别
二维手型识别,也可称为静态二维手势识别,识别的是手势中最简单的一类。这种技术在获取二维信息输入之后,可以识别几个静态的手势,比如握拳或者五指张开。其代表公司是一年前被Google收购的Flutter。在使用了他家的软件之后,用户可以用几个手型来控制播放器。用户将手掌举起来放到摄像头前,视频就开始播放了;再把手掌放到摄像头前,视频又暂停了。
“静态”是这种二维手势识别技术的重要特征,这种技术只能识别手势的“状态”,而不能感知手势的“持续变化”。举个例子来说,如果将这种技术用在猜拳上的话,它可以识别出石头、剪刀和布的手势状态。但是对除此之外的手势,它就一无所知了。所以这种技术说到底是一种模式匹配技术,通过计算机视觉算法分析图像,和预设的图像模式进行比对,从而理解这种手势的含义。
这种技术的不足之处显而易见:只可以识别预设好的状态,拓展性差,控制感很弱,用户只能实现最基础的人机交互功能。但是它是识别复杂手势的第一步,而且我们的确可以通过手势和计算机互动了,还是很酷的不是么?想象一下你忙着吃饭,只要凭空做个手势,计算机就可以切换到下一个视频,比使用鼠标来控制可是方便多了!
二维手势识别
二维手势识别,比起二维手型识别来说稍难一些,但仍然基本不含深度信息,停留在二维的层面上。这种技术不仅可以识别手型,还可以识别一些简单的二维手势动作,比如对着摄像头挥挥手。其代表公司是来自以色列的PointGrab,EyeSight和ExtremeReality。
二维手势识别拥有了动态的特征,可以追踪手势的运动,进而识别将手势和手部运动结合在一起的复杂动作。这样一来,我们就把手势识别的范围真正拓展到二维平面了。我们不仅可以通过手势来控制计算机播放/暂停,我们还可以实现前进/后退/向上翻页/向下滚动这些需求二维坐标变更信息的复杂操作了。
这种技术虽然在硬件要求上和二维手型识别并无区别,但是得益于更加先进的计算机视觉算法,可以获得更加丰富的人机交互内容。在使用体验上也提高了一个档次,从纯粹的状态控制,变成了比较丰富的平面控制。这种技术已经被集成到了电视里,但是目前还是以噱头为主,还不能成为电视的主要常用控制方式。
三维手势识别
接下来我们要谈的就是当今手势识别领域的重头戏——三维手势识别。三维手势识别需要的输入是包含有深度的信息,可以识别各种手型、手势和动作。相比于前两种二维手势识别技术,三维手势识别不能再只使用单个普通摄像头,因为单个普通摄像头无法提供深度信息。要得到深度信息需要特别的硬件,目前世界上主要有3种硬件实现方式。加上新的先进的计算机视觉软件算法就可以实现三维手势识别了。下面就让小编为大家一一道来三维手势识别的三维成像硬件原理。
1结构光(Structure Light)
结构光的代表应用产品就是PrimeSense公司为大名鼎鼎的微软家xbox 360所做的kinect一代了。
这种技术的基本原理是,加载一个激光投射器,在激光投射器外面放一个刻有特定图样的光栅,激光通过光栅进行投射成像时会发生折射,从而使得激光最终在物体表面上的落点产生位移。当物体距离激光投射器比较近的时候,折射而产生的位移就较小;当物体距离较远时,折射而产生的位移也就会相应的变大。这时使用一个摄像头来检测采集投射到物体表面上的图样,通过图样的位移变化,就能用算法计算出物体的位置和深度信息,进而复原整个三维空间。
以Kinect一代的结构光技术来说,因为依赖于激光折射后产生的落点位移,所以在太近的距离上,折射导致的位移尚不明显,使用该技术就不能太精确的计算出深度信息,所以1米到4米是其最佳应用范围。
2光飞时间(Time of Flight)
光飞时间是SoftKinetic公司所采用的技术,该公司为业界巨鳄Intel提供带手势识别功能的三维摄像头。同时,这一硬件技术也是微软新一代Kinect所使用的。
这种技术的基本原理是加载一个发光元件,发光元件发出的光子在碰到物体表面后会反射回来。使用一个特别的CMOS传感器来捕捉这些由发光元件发出、又从物体表面反射回来的光子,就能得到光子的飞行时间。根据光子飞行时间进而可以推算出光子飞行的距离,也就得到了物体的深度信息。
就计算上而言,光飞时间是三维手势识别中最简单的,不需要任何计算机视觉方面的计算。
3多角成像(Multi-camera)
多角成像这一技术的代表产品是Leap Motion公司的同名产品和Usens公司的Fingo。
这种技术的基本原理是使用两个或者两个以上的摄像头同时摄取图像,就好像是人类用双眼、昆虫用多目复眼来观察世界,通过比对这些不同摄像头在同一时刻获得的图像的差别,使用算法来计算深度信息,从而多角三维成像。
在这里我们以两个摄像头成像来简单解释一下:
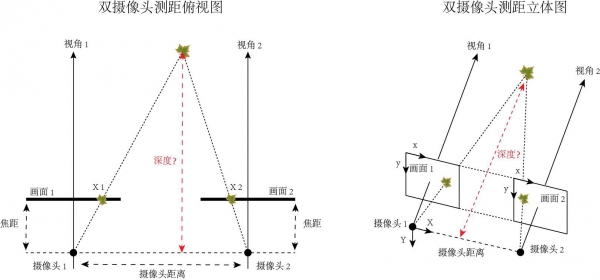
双摄像头测距是根据几何原理来计算深度信息的。使用两台摄像机对当前环境进行拍摄,得到两幅针对同一环境的不同视角照片,实际上就是模拟了人眼工作的原理。因为两台摄像机的各项参数以及它们之间相对位置的关系是已知的,只要找出相同物体(枫叶)在不同画面中的位置,我们就能通过算法计算出这个物体(枫叶)距离摄像头的深度了。
多角成像是三维手势识别技术中硬件要求最低,但同时是最难实现的。多角成像不需要任何额外的特殊设备,完全依赖于计算机视觉算法来匹配两张图片里的相同目标。相比于结构光或者光飞时间这两种技术成本高、功耗大的缺点,多角成像能提供“价廉物美”的三维手势识别效果。
相关链接:
创新大屏交互之——酷炫的体感技术

