


抢CPU饭碗 NVIDIA CUDA技术亮点何在
抢CPU饭碗 NVIDIA CUDA技术亮点何在

|
作为图形芯片领域的领头羊, NVIDIA(英伟达)认为GPU较CPU具有更强的浮点运算能力以及更大的带宽等诸多优势,甚至连晶体管数量目前都是GPU略胜一筹,未来GPU将越来越多地取代CPU的数据处理职能。因此,英伟达在07年就提出了独特的GPGPU(通用图形处理器)概念。目前 NVIDIA(英伟达)新一代GPU都采用了统一渲染架构,这种架构相比以往使GPU的运算单元变得通用,并可以根据图形渲染处理的负载灵活地改变运算单元的任务。这种架构集成了多个支持顶点坐标计算及三角形着色等多级处理的运算单元,各运算单元的任务可以根据各级处理的负载进行调整。新架构的出现也使得在以浮点运算为中心的通用处理中使用GPU成为可能。 在这种趋势下, NVIDIA(英伟达)定制了一个解决方案,被称作Compute Unified Device Architecture,简称CUDA。这也就是今天我们介绍的主角! CUDA的编译 CUDA技术特色 CUDA的运算 由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般CPU是不同的。比如在内存存取latency 的问题上,CPU 通常使用cache 来减少存取主内存的次数,以避免内存latency 影响到执行效率,而显示芯片则多半没有cache(或很小),而利用并行化执行的方式来隐藏内存的latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个thread,依此类推),效率提高不少。正如 NVIDIA(英伟达)公司Tesla GPU计算事业部高级产品经理Sumit Gupta先生曾经推过一个形象的例子,CPU的顺序指令执行操作好比是一间办公室里的多个职员,如果每人需要将杯子里的水倒入同一个桶内时,他们需要排成长队按顺序进行。而对于GPU来说,这些职员无需排队,只要同时走到桶前将水倒入即可。所以,最适合利用CUDA处理的问题,是可以大量并行化的问题,才能有效隐藏内存的latency,并有效利用显示芯片上的大量执行单元。使用CUDA 时,同时有上千个thread在执行是很正常的。因此,如果不能大量并行化的问题,使用CUDA就没办法达到最好的效率了。 CPU存取显卡内存时只能透过PCI Express 接口,因此速度较慢(PCI Express x16 的理论带宽是双向各4GB/s),因此不能过多进行这类动作,以免降低效率。在CUDA架构下,显示芯片执行时的最小单位是thread。数个thread 可以组成一个block。一个block 中的thread 能存取同一块共享的内存,而且可以快速进行同步的动作。每一个block 所能包含的thread 数目是有限的,不过执行相同程序的block,可以组成grid。不同block中的thread无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同block中的thread能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的thread数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个block中的thread顺序执行,而非同时执行。不同的grid则可以执行不同的程序。 在目前支持CUDA的GPU中,其流处理器个数是不能和CPU现在拥有的内核数量作类比的。CPU的每一个核心都是一个完整的独立处理架构,而GPU中的每个流处理器并不完全是这样,而是以子组合方式运作,比如每8个流处理器组成一个Stream Multiprocessors (SM),其中分为四个流处理器又分为1小组,也可以看成是有两组4D的SIMD处理器。需要说明的是,若用户拥有超过两张或以上支持CUDA的显卡,驱动程序将通过PCIe总线自动分配工作负载,进一步提升效能。 当然CUDA也有其弱势的地方,并不是所有的事情CUDA都能够很好地解决,比如像操作系统这样复杂的指令和纷繁的分支循环而又用很少的线程来处理,这显然就不是CUDA的强项了。高度并行的计算是CUDA的技术特性之一。 哪些GPU支持CUDA? 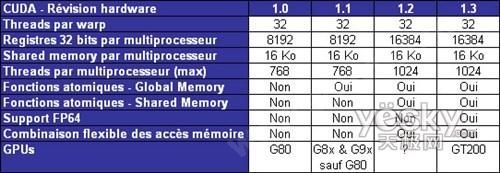 不同CUDA版本对比 CUDA 2.0—随GeForce GTX 200登场 每一个多重处理器都包含了8个主要的FMAD处理器和8和MUL处理器来实现一些特殊功能的计算等。这样,一个64位的FMAD处理器就产生了。但是这样的处理器对于64位的计算能力相当低下,8X的低速FMAD和16X的低速FMUL都是导致计算能力低下的原因。这个支持64位也意味着可以以它为模板为将来的更高级和新一代的GPU发展提供代码或者应用程序的支持,从而得到更好的甚至超过一个以上的64位处理器。每一个多重处理器都具有两个流处理线,这样就不必依赖周期而同时处理两个信号。 引入双精度运算能力,可以在一定程度上增强GT200在科学计算领域的适用性.尽管在实际的相关领域中其实有部分甚至只需要16位精度就足够了,但GTX200核心的每一个SM都包括了一个双精度64Bit浮点运算单元,所以每个周期GT200能达成1MAD*30SM=30MAD,在1.5GHz的shader频率下可以达到90 GFLOPS(MAD)的双精度浮点性能, NVIDIA(英伟达)对其称之为可以与8核Xeon处理器(我想应该是指45nm Hypertown内核Xeon E5440 2.83GHz)的水平。不过需要注意的是,Xeon每个内核的浮点单元组合是每两个周期完成一个ADDPD或者一个周期完成一个MULPD,在双精度浮点峰值性能上"含金量"方面似乎要比GT200每个SM单周期MAD高一些。 NVIDIA(英伟达)的对手AMD在RV670上实现了硬件(非模拟)的FP64支持,双精度MAD性能为单精度MAD的1/5,GT200架构的双精度浮点支持应该是 NVIDIA(英伟达)迈向双精度浮点加速器的第一步,未来的架构很可能会把浮点双精度的性能做到单精度的1/2水平,这将是非常可观的。 目前CUDA已经应用在很多领域,包括在通用计算中的一些GPU加速,游戏中的物理模拟等等,而在科学计算中,CUDA可发挥的功效就更大了。比如有限元的计算、神经元的研究计算、地质分析等等科学研究的领域;当然目前GPU计算的应用还是处于一个早期的阶段,大部分CUDA应用都是专业人员和相关的程序员在开发,随着CUDA的广泛推行,以后会有实际的基于CUDA的程序,更多的程序员能够加入进来,并且开发一些可以给大家日常应用带来好处的程序,只要有支持CUDA的GPU就能够利用到GPU计算的好处。 >>相关产品 |

